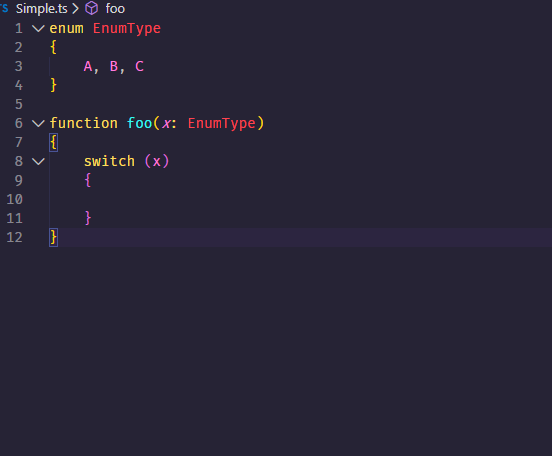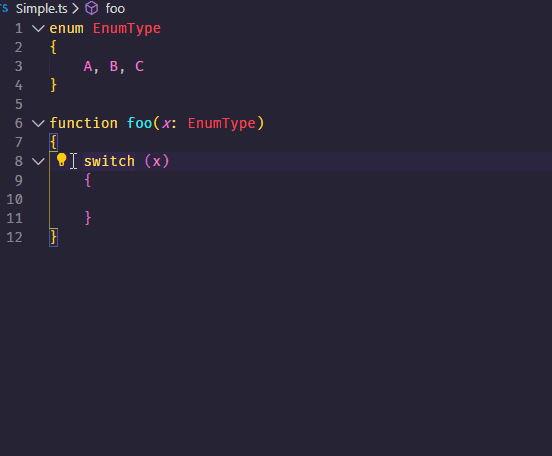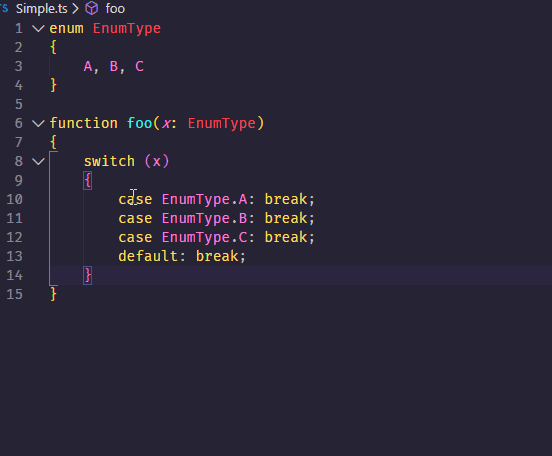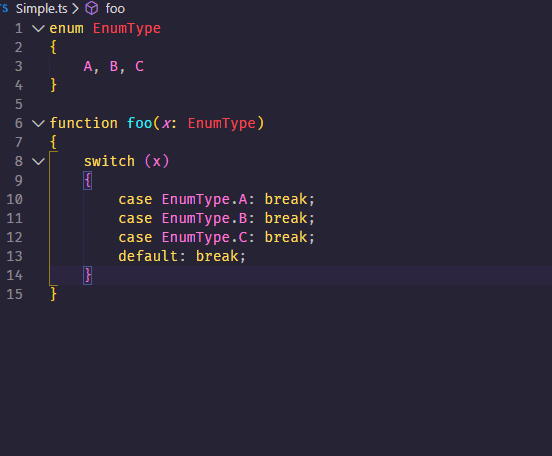
First of all the Retrieve operator is used for loading the 'Golf' data set. Then the Select Attributes operator is applied on it to select the required attributes. If we select only the Play and Wind attributes as in the query, then the coming operators cannot be applied. You will see later that the attribute set will be reduced automatically, thus the Select Attributes operator is not really required here. Then the Filter Examples operator is applied to pre-exclude examples where the Outlook attribute has the value 'overcast'. Then the Aggregate operator is applied on the remaining examples.

Firstly, it specifies the aggregation functions using the aggregation attributes parameter. We need averages of the Temperature and Humidity attribute; this is specified using the aggregation attributes parameter. Secondly, we do not want the averages of the entire data set. We want the averages by groups, grouped by the Play and Wind attribute values.

These groups are specified using the group by attributes parameter of the Aggregate operator. Thirdly, required attributes are automatically filtered by this operator. Only those attributes appear in the resultant data set that have been specified in the Aggregate operator. Next, we are interested only in those examples where the average Temperature is greater than 71. This condition can be applied using the Filter Examples operator. Breakpoints are inserted after every operator in the Example Process so that you can understand the part played by each operator.
The SQL language treats the empty set differently when using aggregate functions. Without a GROUP BY clause, a query containing an aggregate function over zero input rows will return a single row as the result. In the case of COUNT, its result will be the value zero, and with all other aggregate functions the result will be NULL. However, if the query contains a GROUP BY clause, and the input to the query is empty, then the query's result is empty and no rows are returned.

Aggregate functions return a single result row based on groups of rows, rather than on single rows. Aggregate functions can appear in select lists and in ORDER BY and HAVING clauses. They are commonly used with the GROUP BY clause in a SELECT statement, where Oracle Database divides the rows of a queried table or view into groups. In a query containing a GROUP BY clause, the elements of the select list can be aggregate functions, GROUP BY expressions, constants, or expressions involving one of these. Oracle applies the aggregate functions to each group of rows and returns a single result row for each group. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group.

It is better to identify each summary row by including the GROUP BY clause in the query resulst. All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them. The OpenAccessLinqDataSource control enables you to group data by one or more columns. You use the GroupBy option to specify which properties are used for consolidating data records that have the same values.

For example, if you set the Key Member to Make, all the records in the query that have the same Make property value are returned as a single consolidated record. The GroupBy statement is used in conjunction with the aggregate functions to group the result set by one or more columns. This topic illustrates how to use the OpenAccessLinqDataSource control to group and aggregate data. Except COUNT function,all the aggregate functions do not consider NULL values.

When an aggregate function is used in a query without the GROUP BY clause, the aggregate function aggregates the entire result set . If you do not use the GROUP BY clause, some aggregate functions in the SELECT list can only be used with other aggregate functions. That's why the aggregate function must use the GROUP BY clause to connect to the list in the SELECT list. Spark also supports advanced aggregations to do multiple aggregations for the same input record set via GROUPING SETS, CUBE, ROLLUP clauses.

The grouping expressions and advanced aggregations can be mixed in the GROUP BY clause and nested in a GROUPING SETS clause. See more details in the Mixed/Nested Grouping Analytics section. When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function. DISTINCT and UNIQUE, which are synonymous, cause an aggregate function to consider only distinct values of the argument expression. The syntax diagrams for aggregate functions in this chapter use the keyword DISTINCT for simplicity.

Let's see how the raw aggregation function rawsum() treats the two sample time series from the previous section. The following chart shows that rawsum(), like sum(), produces a result for every moment in time that a data point is reported by at least one input series. You can use raw aggregation functions instead of standard aggregation functions if you want the results to be based on actual reported values, without any interpolated values. For example, you might use raw aggregation results as a way of detecting when one or more input time series fail to report a value. Let us assume a scenario where we want to apply certain aggregation functions on the Golf data set. We don't want to include examples where the Outlook attribute has the value 'overcast'.

We group the remaining examples of the 'Golf' data set by values of the Play and Wind attributes. We wish to find the average Temperature and average Humidity for these groups. Once these averages have been calculated, we want to see only those examples where the average Temperature is above 71. Lastly, we want to see the results in ascending order of the average Temperature. The Aggregate operator creates a new ExampleSet from the input ExampleSet showing the results of the selected aggregation functions.

Many aggregation functions are supported including SUM, COUNT, MIN, MAX, AVERAGE and many other similar functions known from SQL. The functionality of the GROUP BY clause of SQL can be imitated by using the group by attributes parameter. You need to have a basic understanding of the GROUP BY clause of SQL for understanding the use of this parameter because it works exactly the same way.

If you want to imitate the known HAVING clause from SQL, you can do that by applying the Filter Examples operator after the Aggregation operator. It focuses on obtaining summary information, such as averages and counts etc. It can group examples in an ExampleSet into smaller sets and apply aggregation functions on those sets.

Please study the attached Example Process for better understanding of this operator. The HAVING search condition is applied to the rows in the output produced by grouping. Only the groups that meet the search condition appear in the result.

You can apply a HAVING clause only to columns that appear in the GROUP BY clause or in an aggregate function. The above example, returns error because there is a non-group functional column is used with an aggregate function MAX. So the SELECT statement returns all rows for Deptnumber column but aggregate function returns only one row. Oracle Aggregate function is a type of function which operates on specified column and returns a single row result. The pandas standard aggregation functions and pre-built functions from the python ecosystem will meet many of your analysis needs. However, you will likely want to create your own custom aggregation functions.

The easiest way to see the results of an aggregation function is when all of the input series report their data points at exactly the same time. This causes the points at any given timestamp to all line up. The aggregation function operates on the values in each lineup of points, and returns each result in a point at the corresponding timestamp. These functions aggregate multiple series down, usually to a single series. The WHERE clause pre-excludes the examples where the Outlook attribute has value 'overcast'.

The GROUP BY clause groups the data set according to the specified attributes. The HAVING clause filters the results after the aggregation functions have been applied. Finally the ORDER BY clause sorts the results in ascending order of the Temperature averages.

The result is returned at the end and the returned result can be directly output or saved to the collection. Listing 6.4 and Figure 6.4 shows some queries that involve AVG(). The first query returns the average price of all books if prices were doubled.

The second query returns the average and total sales for business books; both calculations are null because the table contains no business books. The third query uses a subquery to list the books with above-average sales. And finally, we will also see how to do group and aggregate on multiple columns. The BIT_AND(), BIT_OR(), and BIT_XOR() aggregate functions perform bit operations. Prior to MySQL 8.0, bit functions and operators required BIGINT (64-bit integer) arguments and returned BIGINT values, so they had a maximum range of 64 bits. Non-BIGINT arguments were converted to BIGINT prior to performing the operation and truncation could occur.
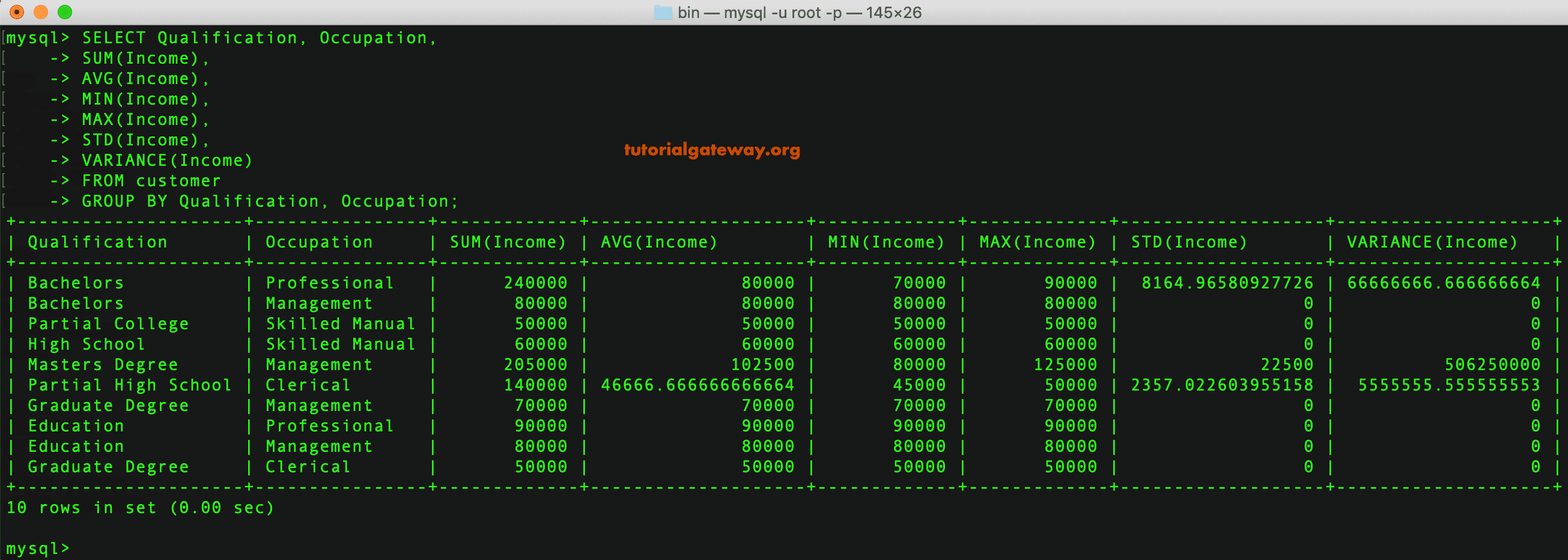
Table 9-50 shows aggregate functions typically used in statistical analysis. In all cases, null is returned if the computation is meaningless, for example when N is zero. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query.

Now we use the sum() function to aggregate these two time series. In the following chart, we see that sum() produces a result for every moment in time that a data point is reported by at least one input series. Whenever both series report a data point at the same time , sum() returns a data point whose value is the sum of both reported points.

The Group by clause is often used to arrange identical duplicate data into groups with a select statement to group the result-set by one or more columns. This clause works with the select specific list of items, and we can use HAVING, and ORDER BY clauses. Group by clause always works with an aggregate function like MAX, MIN, SUM, AVG, COUNT.
When grouping, you can apply an aggregation function to any column to populate the group row with values. You can pick from the grid's built in aggregation functions or provide your own. It filters non-aggregated rows before the rows are grouped together. To filter grouped rows based on aggregate values, use the HAVING clause. The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined.

Specifies an expression that can appear in the select list of a query. Can contain constants, row values, operators, scalar functions, and scalar subqueries. The value is cast to char data type before being concatenated.
Takes two column names or expressions as arguments, the first of these being used as a key and the second as a value, and returns a JSON object containing key-value pairs. Returns NULL if the result contains no rows, or in the event of an error. An error occurs if any key name is NULL or the number of arguments is not equal to 2. For discussion about argument evaluation and result types for bit operations, see the introductory discussion in Section 12.13, "Bit Functions and Operators". The most common aggregation functions are a simple average or summation of values. As of pandas 0.20, you may call an aggregation function on one or more columns of a DataFrame.

The GROUP BY clause divides the rows returned from the SELECTstatement into groups. For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. If you omit the GROUP BY clause, then Oracle applies aggregate functions in the select list to all the rows in the queried table or view.
The GROUP BY clause is normally used along with five built-in, or "aggregate" functions. These functions perform special operations on an entire table or on a set, or group, of rows rather than on each row and then return one row of values for each group. For those cases, consider using raw aggregation, which comes at the cost of slightly less precision. Each aggregation function accepts a 'group by' parameter that allows you to subdivide the input time series into groups, and request separate aggregates for each group. Each blue point produced by sum() is the result of adding the data values reported by the input series at the same minute. When you group values, the Data Integration Service produces one row for each group.

If you do not group values, the Data Integration Service returns one row for all input rows. The Data Integration Service returns the last row of each group with the result of the aggregation. For example, if you use the FIRST aggregator function, the Data Integration Service returns the first row. To define a group for the aggregate expression, select the appropriate input, input/output, output, and variable ports in the Aggregator transformation. You can select multiple group by ports to create a new group for each unique combination. The Data Integration Service then performs the defined aggregation for each group.

The output from a groupby and aggregation operation varies between Pandas Series and Pandas Dataframes, which can be confusing for new users. As a rule of thumb, if you calculate more than one column of results, your result will be a Dataframe. For a single column of results, the agg function, by default, will produce a Series. We did not tell GroupBy which column we wanted it to apply the aggregation function on, so it applied it to all the relevant columns and returned the output. MAX() may take a string argument; in such cases, it returns the maximum string value. The DISTINCT keyword can be used to find the maximum of the distinct values of expr, however, this produces the same result as omitting DISTINCT.
One area that needs to be discussed is that there are multiple ways to call an aggregation function. As shown above, you may pass a list of functions to apply to one or more columns of data. It should be noted that except for count, these functions return a null value when no rows are selected.